About me
I’m a CS PhD student at WashU in the Multimodal Vision Research Laboratory (MVRL), advised by Prof. Nathan Jacobs. I have over five years of industry experience focusing on perception algorithms for autonomous driving and robotics. My research interests include computer vision, deep learning, and robotics. My current research is focusing on Content Generation and 3DV.
I am in the intern market for 2026, so feel free to reach out if you think I am a good fit for your team!
News
- Jun 2025, our work GenStereo was accepted by ICCV 2025.
- Jul 2024, one paper was accepted by ECCV 2024.
- Apr 2024, I will join WashU CSE as a PhD student.
- Apr 2024, our work QuadFormer was accepted by UR 2024.
- Nov 2023, our work StereoFlowGAN was accepted by BMVC 2023.
Publications
 | MCPDepth: Panorama Depth Estimation from Multi Cylindrical Panorama by Stereo Matching Feng Qiao, Zhexiao Xiong, Nathan Jacobs, Xinge Zhu, Yuexin Ma, Qiumeng He. We introduce Multi-Cylindrical Panoramic Depth Estimation (MCPDepth), a two-stage framework for omnidirectional depth estimation via stereo matching between multiple panoramas. MCPDepth uses cylindrical panoramas for initial stereo matching and then fuses the resulting depth maps across views. A circular attention module is used to overcome the distortion along the vertical axis. MCPDepth uses only standard network components, making deployment to embedded devices significantly simpler than prior approaches that require custom kernels. We theoretically and experimentally compare spherical and cylindrical projections for stereo matching, highlighting the advantages of the cylindrical projection. MCPDepth achieves state-of-the-art performance with an 18.8% reduction in mean absolute error (MAE) for depth on the outdoor, synthetic dataset Deep360 and a 19.9% reduction on the indoor, real-scene dataset 3D60. The code is attached and will be available after acceptance. |
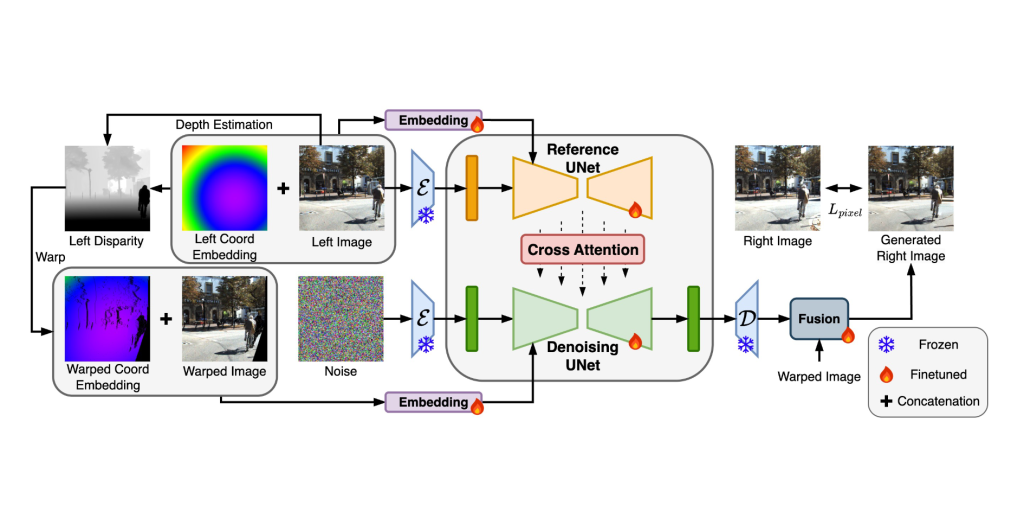 | Towards Open-World Generation of Stereo Images and Unsupervised Matching Feng Qiao, Zhexiao Xiong, Eric Xing, Nathan Jacobs. International Conference on Computer Vision (ICCV), 2025 Stereo images are fundamental to numerous applications, including extended reality (XR) devices, autonomous driving, and robotics. Unfortunately, acquiring high-quality stereo images remains challenging due to the precise calibration requirements of dual-camera setups and the complexity of obtaining accurate, dense disparity maps. Existing stereo image generation methods typically focus on either visual quality for viewing or geometric accuracy for matching, but not both. We introduce GenStereo, a diffusion-based approach, to bridge this gap. The method includes two primary innovations (1) conditioning the diffusion process on a disparity-aware coordinate embedding and a warped input image, allowing for more precise stereo alignment than previous methods, and (2) an adaptive fusion mechanism that intelligently combines the diffusion-generated image with a warped image, improving both realism and disparity consistency. Through extensive training on 11 diverse stereo datasets, GenStereo demonstrates strong generalization ability. GenStereo achieves state-of-the-art performance in both stereo image generation and unsupervised stereo matching tasks. Our framework eliminates the need for complex hardware setups while enabling high-quality stereo image generation, making it valuable for both real-world applications and unsupervised learning scenarios. |
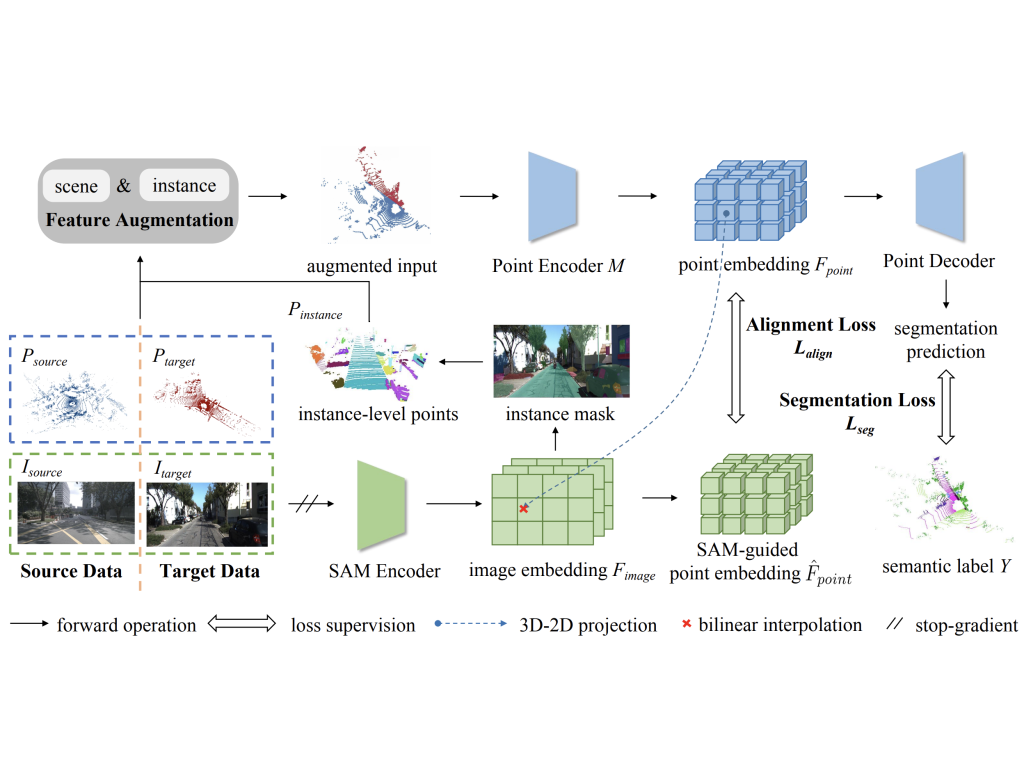 | SAM-guided Unsupervised Domain Adaptation for 3D Segmentation Xidong Peng, Runnan Chen, Feng Qiao, Lingdong Kong, Youquan Liu, Tai Wang, Xinge Zhu, Yuexin Ma. European Conference on Computer Vision (ECCV), 2024 Inspired by the remarkable generalization capabilities exhibited by the vision foundation model, SAM, in the realm of image segmentation, our approach leverages the wealth of general knowledge embedded within SAM to unify feature representations across diverse 3D domains and further solves the 3D domain adaptation problem. Specifically, we harness the corresponding images associated with point clouds to facilitate knowledge transfer and propose an innovative hybrid feature augmentation methodology, which significantly enhances the alignment between the 3D feature space and SAM’s feature space, operating at both the scene and instance levels. Our method is evaluated on many widely-recognized datasets and achieves state-of-the-art performance. |
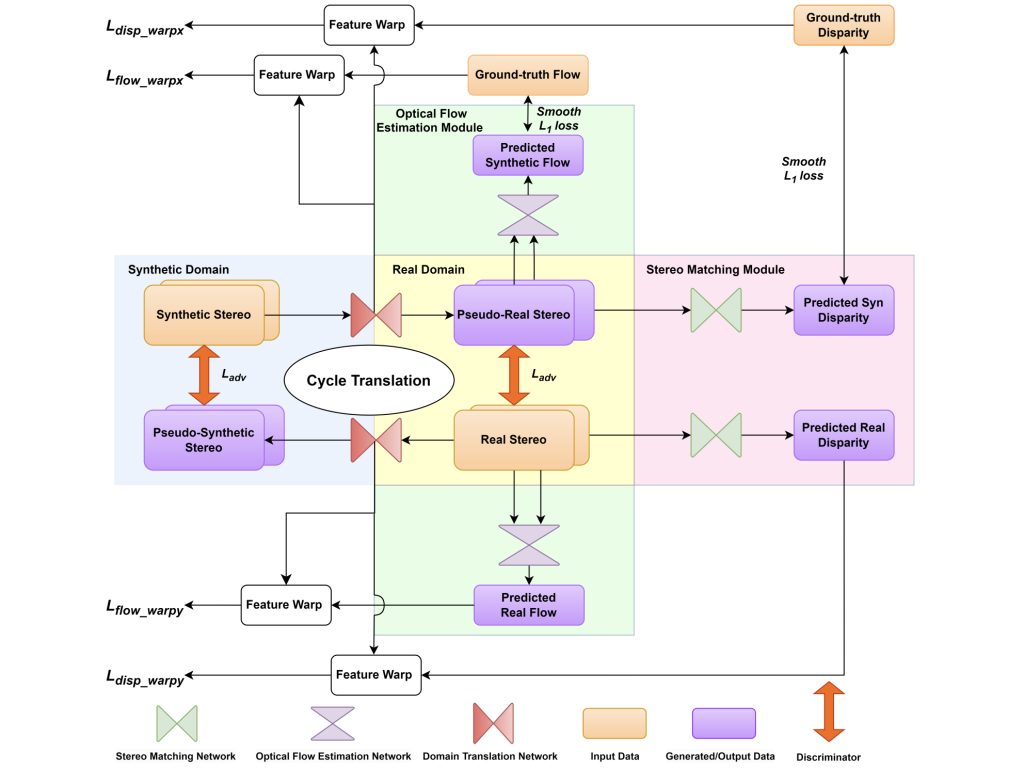 | StereoFlowGAN: Co-training for Stereo and Flow with Unsupervised Domain Adaptation Zhexiao Xiong, Feng Qiao, Yu Zhang, Nathan Jacobs. The British Machine Vision Conference (BMVC), 2023 We introduce a novel training strategy for stereo matching and optical flow estimation that utilizes image-to-image translation between synthetic and real image domains. Our approach enables the training of models that excel in real image scenarios while relying solely on ground-truth information from synthetic images. To facilitate task-agnostic domain adaptation and the training of task-specific components, we introduce a bidirectional feature warping module that handles both left-right and forward-backward directions. Experimental results show competitive performance over previous domain translation-based methods, which substantiate the efficacy of our proposed framework, effectively leveraging the benefits of unsupervised domain adaptation, stereo matching, and optical flow estimation. |
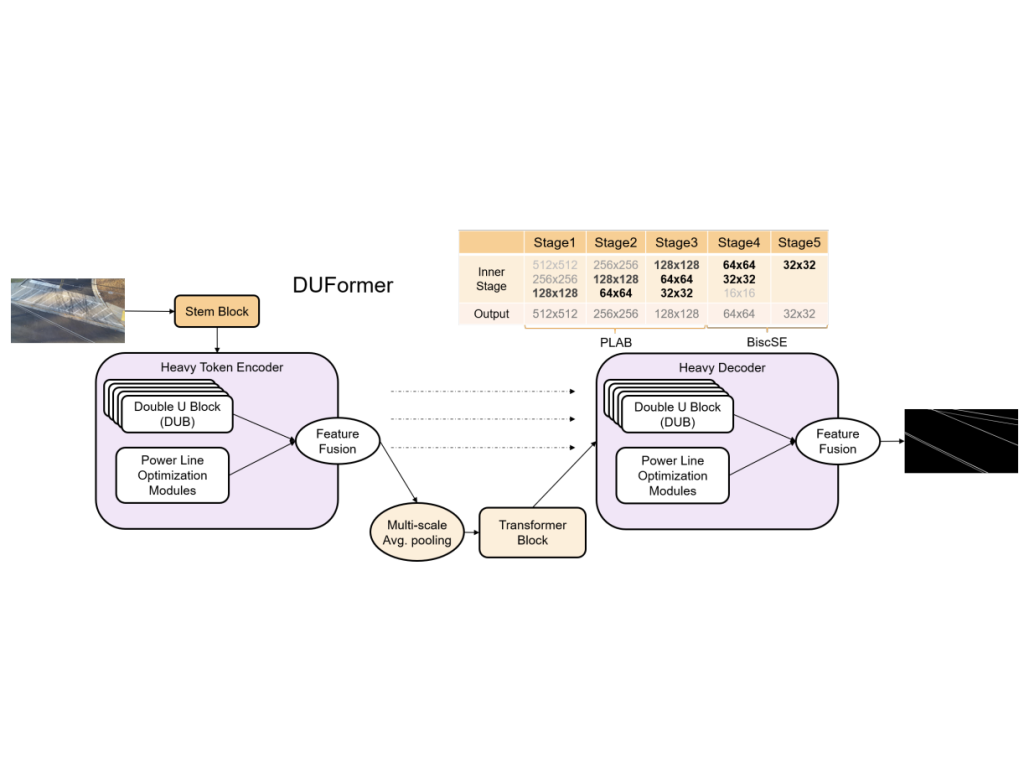 | DUFormer: Solving Power Line Detection Task in Aerial Images using Semantic Segmentation Deyu An, Qiang Zhang, Jianshu Chao, Ting Li, Feng Qiao, Yong Deng, Zhenpeng Bian. Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 2023 We proposed DUFormer, a CNN-Transformer hybrid algorithm, is specifically designed to detect power lines in aerial images. |
 | QuadFormer: Quadruple Transformer for Unsupervised Domain Adaptation in Power Line Segmentation of Aerial Images Pratyaksh Prabhav Rao*, Feng Qiao*, Weide Zhang, Yiliang Xu, Yong Deng, Guangbin Wu, Qiang Zhang. International Conference on Ubiquitous Robots (UR), 2024 we propose QuadFormer, a novel framework designed for domain adaptive semantic segmentation. The hierarchical quadruple transformer combines cross-attention and self-attention mechanisms to adapt transferable context. Based on cross-attentive and self-attentive feature representations, we introduce a pseudo label correction scheme to online denoise the pseudo labels and reduce the domain gap. Additionally, we present two datasets - ARPLSyn and ARPLReal to further advance research in unsupervised domain adaptive powerline segmentations. |
 | STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes Peishan Cong, Xinge Zhu, Feng Qiao, Yiming Ren, Xidong Peng, Yuenan Hou, Lan Xu, Ruigang Yang, Dinesh Manocha, Yuexin Ma. Conference on Computer Vision and Pattern Recognition (CVPR), 2022 We introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets. |
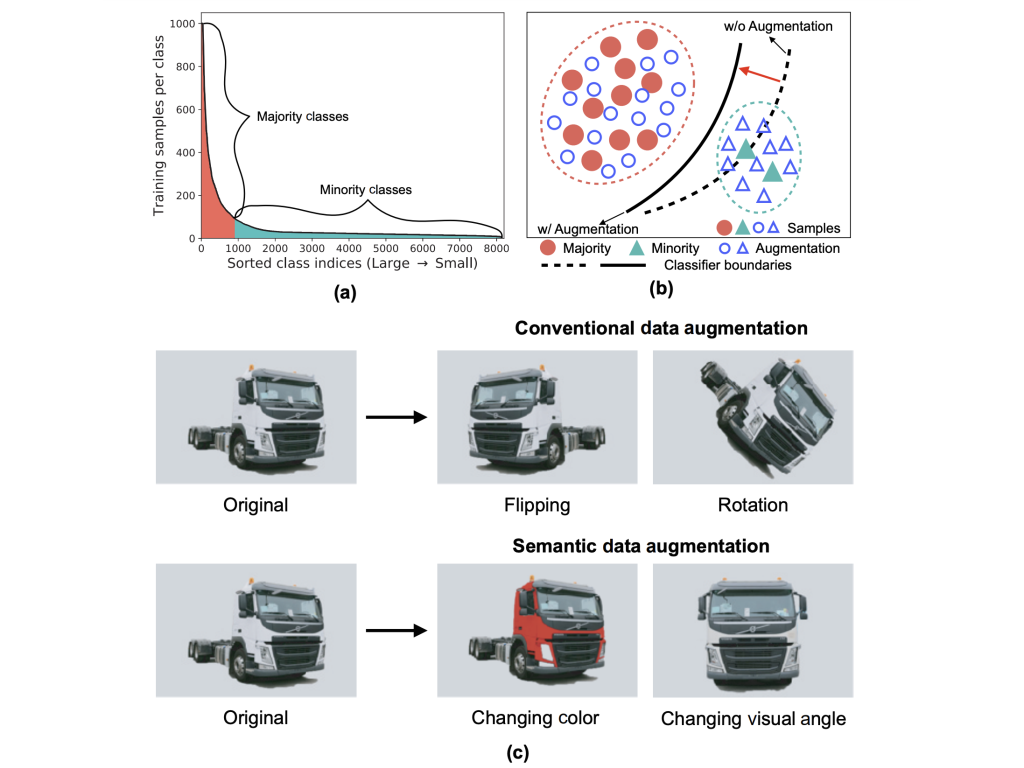 | MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition Li, Shuang, Kaixiong Gong, Chi Harold Liu, Yulin Wang, Feng Qiao, and Xinjing Cheng. Conference on Computer Vision and Pattern Recognition (CVPR), 2021 We propose a novel approach to learn transformed semantic directions with meta-learning automatically. In specific, the augmentation strategy during training is dynamically optimized, aiming to minimize the loss on a small balanced validation set, which is approximated via a meta update step. Extensive empirical results on CIFAR-LT-10/100, ImageNet-LT, and iNaturalist 2017/2018 validate the effectiveness of our method. |
Projects
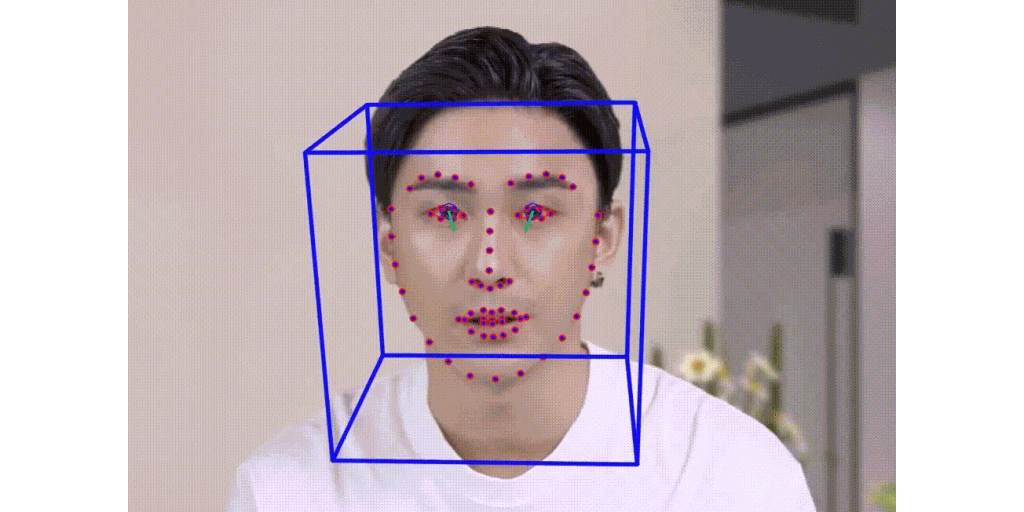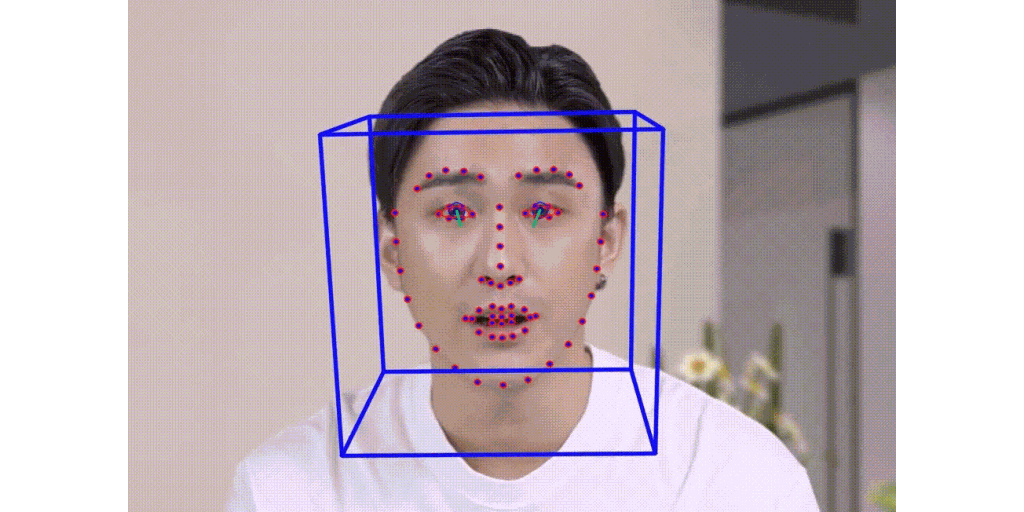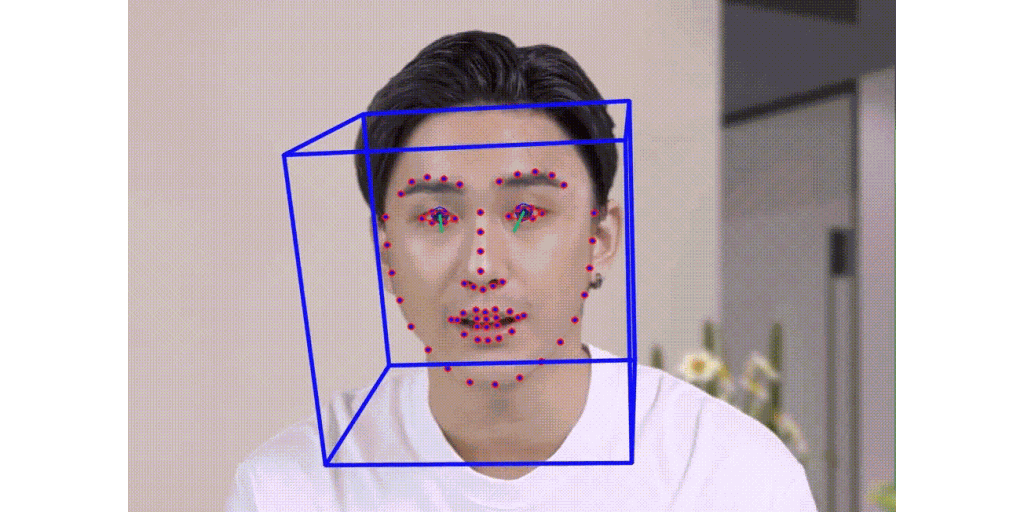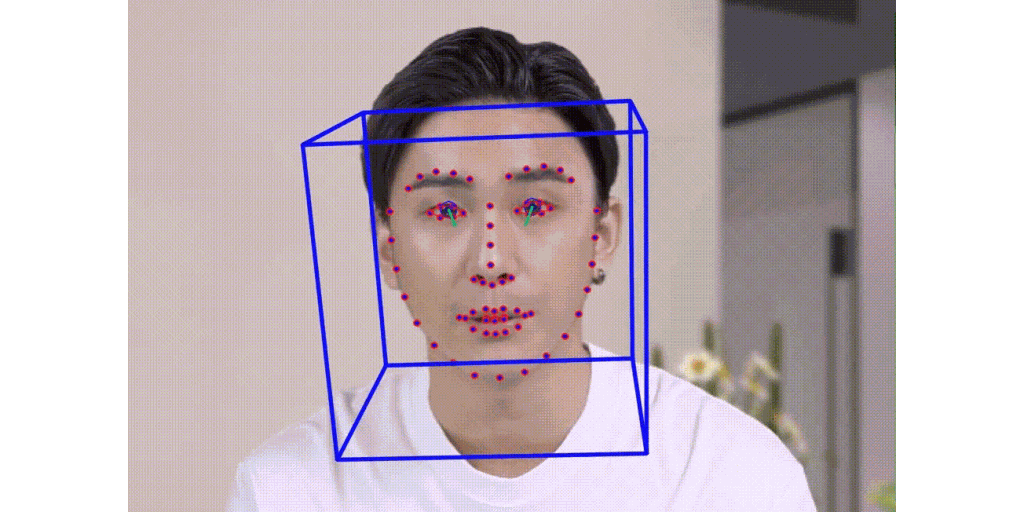
Talking Face Generation
Click for details
Multi stage talking face generation.

3D Reconstruction of Electric Tower
Click for details
3D reconstruction of electric tower using aerial images.

3D Reconstruction with Stereo Fisheye Cameras
Click for details
Unsupervised depth estimation with stereo fisheye cameras.

Self-supervised Depth Estimation using Stereo Cameras
Click for details
Depth estimation using stereo cameras. Synthetic data is utilized to generate ground truth, and domain adaptation/generalization is employed to ensure excellent performance on real data as well.

3D Object Detection and Tracking using Multi-LiDARs
Click for details
3D object detection and tracking using multi-lidars. Inputs are sequential point clouds from multi-lidars and the model can get the 3D information of objects including position, size, orientation, class, free space (also as known as drivable area), and lanes. The model is deployed on GPU with TensorRT and SoC chip, which meets the needs of real-time detection.

3D Object Detection and Tracking using Monocular Camera 
Click for details
3D object detection and tracking using a monocular camera. The model takes sequential images as inputs and is capable of extracting 3D information about objects, including their position, size, orientation, and class. Deployment on a GPU with TensorRT enables the model to achieve an impressive inference speed of 50 Hz.
Honors and Awards
- ITSC 2024 Best Paper Award
- Outstanding Graduates.
- Outstanding scholarship.
- Outstanding student leaders.
- National Scholarship (top 1%, highest scholarship in China).
Services
Conference Reviewer
CVPR (2025, 2024, 2023), ICCV (2025), ECCV (2024), AAAI (2026, 2025), WACV (2026), ITSC (2025, 2024)
Journal Reviewer
IEEE Transactions on Intelligent Transportation Systems (T-ITS) (2023-present), IEEE Transactions on Intelligent Vehicles (T-IV) (2024-present), Journal of Automobile Engineering (JAUTO) (2023-present), International Journal of Vehicle Design (IJVD) (2023-present)