About me
I’m a CS PhD candidate at WashU in the Multimodal Vision Research Laboratory (MVRL), advised by Prof. Nathan Jacobs. I have over five years of industry experience focusing on perception algorithms for autonomous driving and robotics. My research interests include computer vision, deep learning, and robotics. My current research focuses on Image/Video Generation, 3D Vision (3DV), and Vision-Language-Action (VLA).
News
- Mar 2026, our work MCPDepth was accepted by CVPR 2026 Omnidirectional Computer Vision 6th Workshop.
- Jun 2025, our work GenStereo was accepted by ICCV 2025.
- Jul 2024, one paper was accepted by ECCV 2024.
- Apr 2024, I will join WashU CSE as a PhD student.
- Apr 2024, our work QuadFormer was accepted by UR 2024.
- Nov 2023, our work StereoFlowGAN was accepted by BMVC 2023.
Publications
| Track2View: 4D-Consistent Camera-Controlled Video Generation via Paired 3D Point Tracks 🌟 Feng Qiao, Zhaochong An, Zhexiao Xiong, Serge Belongie, Nathan Jacobs arXiv, 2026 arXiv Code Project #Generation#Video#Camera#3D | |
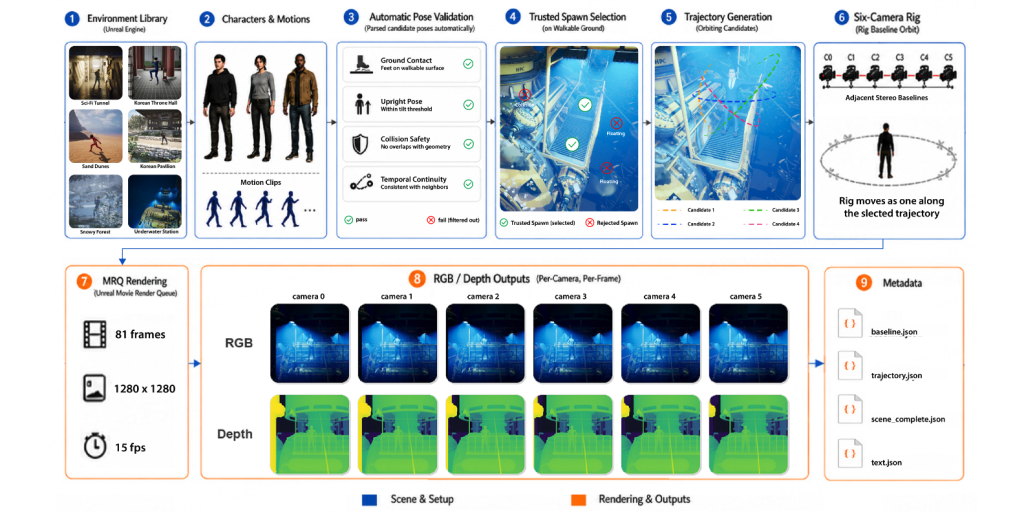 | StereoGenBench: A Synthetic Multi-Camera Benchmark for Stereo Generation under Controlled Baseline Regimes Yangzhi Cui*, Feng Qiao*, Nathan Jacobs arXiv, 2026 arXiv Dataset #Stereo#Generation#Benchmark |
 | GenOpticalFlow: A Generative Approach to Unsupervised Optical Flow Learning Yixuan Luo*, Feng Qiao*, Zhexiao Xiong, Yanjing Li, Nathan Jacobs arXiv, 2026 arXiv #Generation#OpticalFlow |
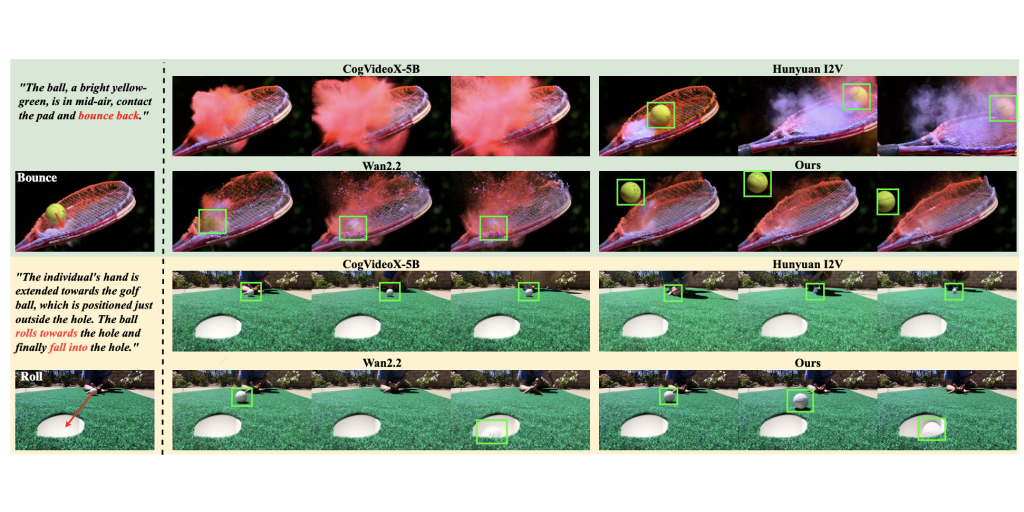 | PhysAlign: Physics-Coherent Image-to-Video Generation through Feature and 3D Representation Alignment Zhexiao Xiong, Yizhi Song, Liu He, Wei Xiong, Yu Yuan, Feng Qiao, Nathan Jacobs arXiv, 2026 arXiv Project #Generation#Video#3D |
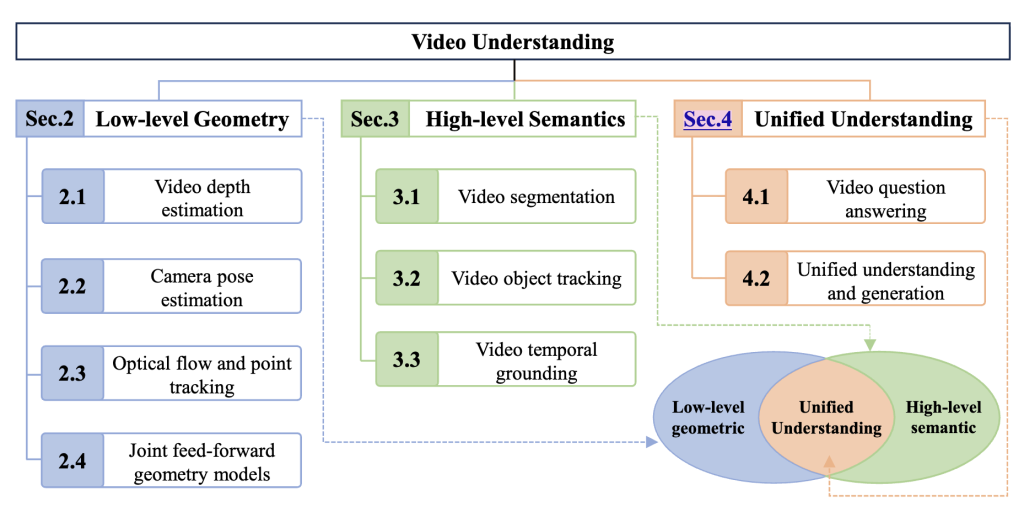 | Video Understanding: From Geometry and Semantics to Unified Models Zhaochong An, Zirui Li, Mingqiao Ye, Feng Qiao, Jiaang Li, Zongwei Wu, Vishal Thengane, Chengzu Li, Lei Li, Luc Van Gool, Guolei Sun, Serge Belongie Machine Intelligence Research (MIR), 2026 arXiv #Survey#Video |
 | MCPDepth: Panorama Depth Estimation from Multi Cylindrical Panorama by Stereo Matching 🌟 Feng Qiao, Zhexiao Xiong, Xinge Zhu, Yuexin Ma, Qiumeng He, Nathan Jacobs CVPR Omnidirectional Computer Vision Workshop, 2026 arXiv Code #Stereo#Depth#Panorama |
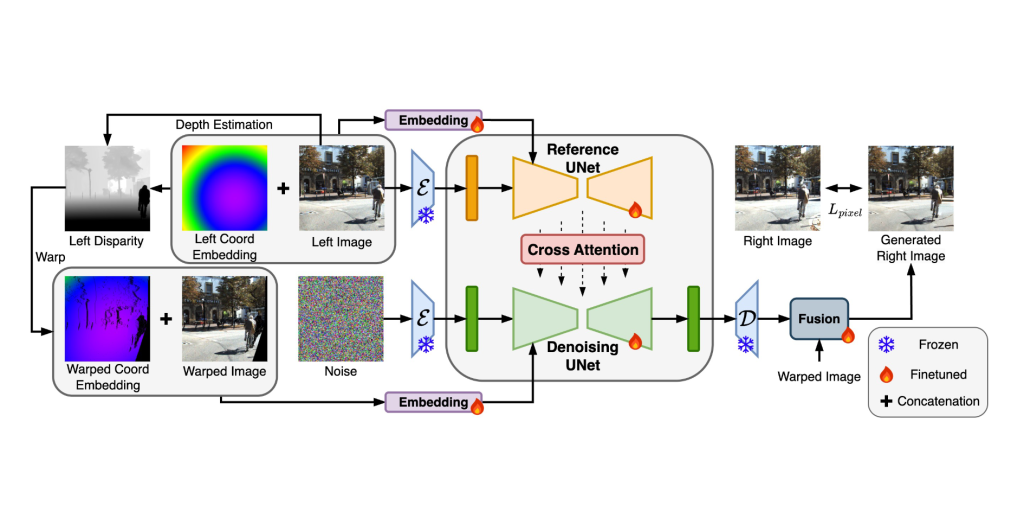 | Towards Open-World Generation of Stereo Images and Unsupervised Matching 🌟 Feng Qiao, Zhexiao Xiong, Eric Xing, Nathan Jacobs ICCV, 2025 arXiv Code Project Demo Models #Stereo#Generation#Diffusion |
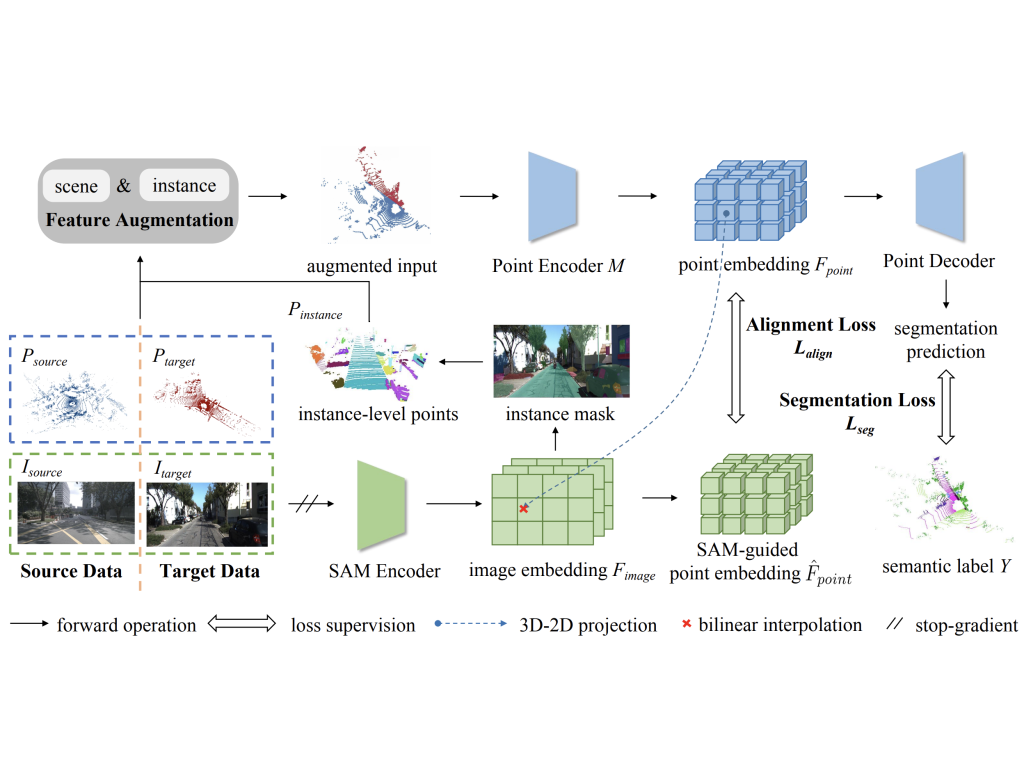 | SAM-guided Unsupervised Domain Adaptation for 3D Segmentation Xidong Peng, Runnan Chen, Feng Qiao, Lingdong Kong, Youquan Liu, Tai Wang, Xinge Zhu, Yuexin Ma ECCV, 2024 arXiv #3DSeg#DomainAdapt#SAM |
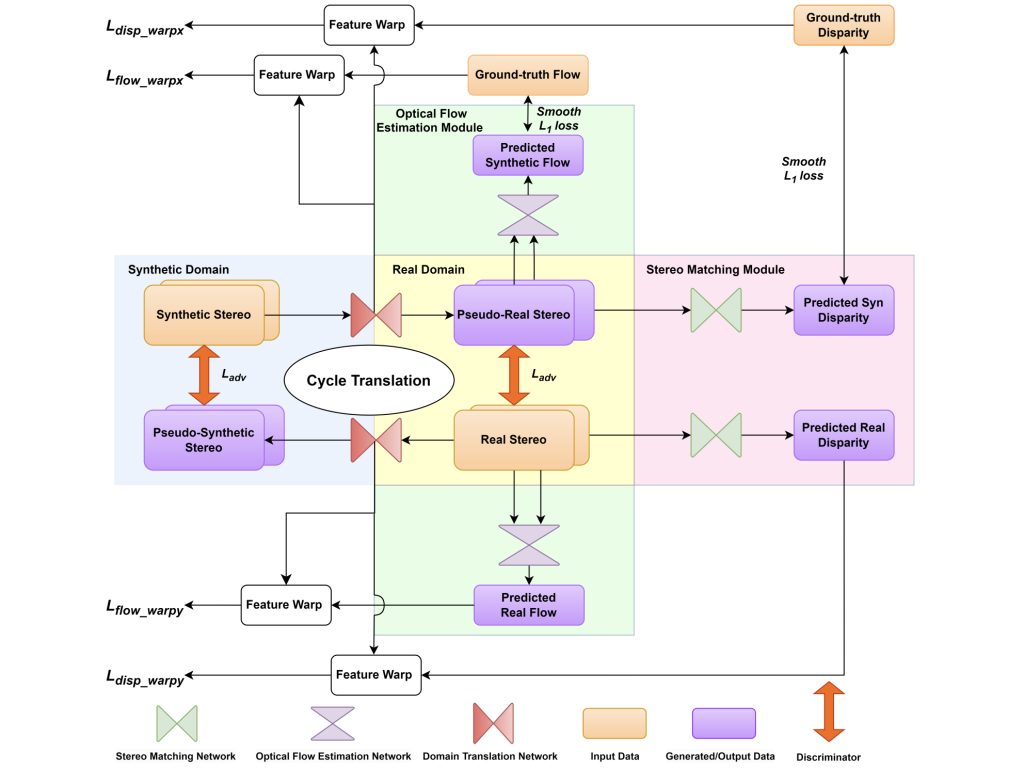 | StereoFlowGAN: Co-training for Stereo and Flow with Unsupervised Domain Adaptation Zhexiao Xiong, Feng Qiao, Yu Zhang, Nathan Jacobs BMVC, 2023 arXiv #Stereo#OpticalFlow#DomainAdapt |
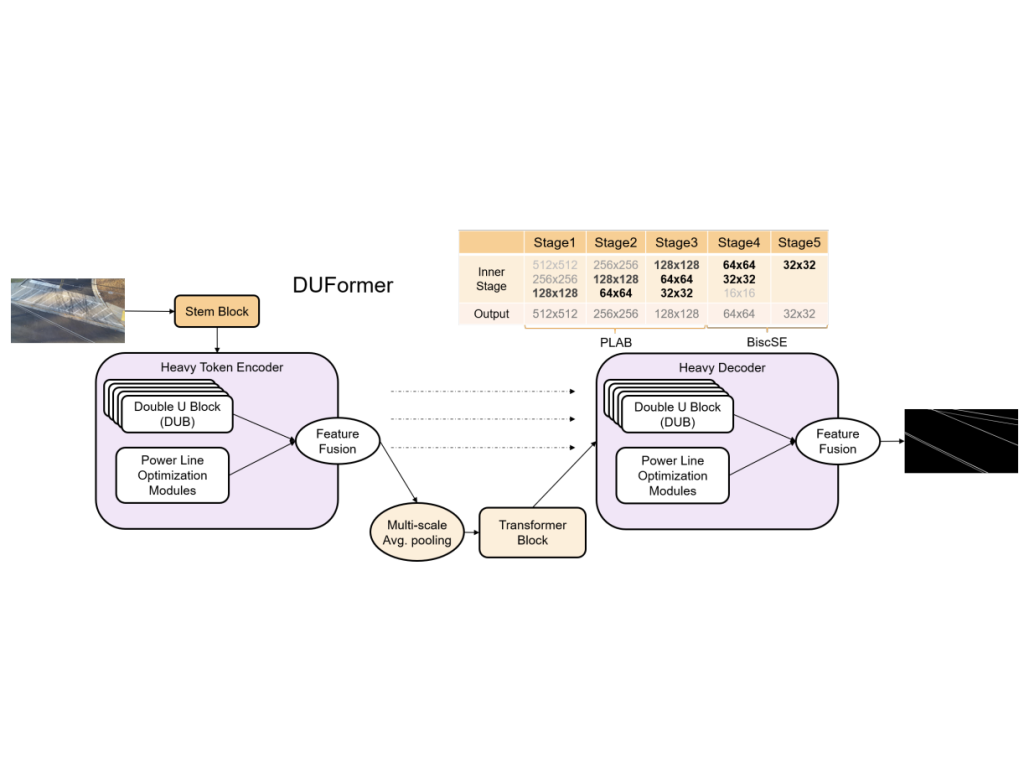 | DUFormer: Solving Power Line Detection Task in Aerial Images using Semantic Segmentation Deyu An, Qiang Zhang, Jianshu Chao, Ting Li, Feng Qiao, Yong Deng, Zhenpeng Bian PRCV, 2023 arXiv #Segmentation#PowerLine |
 | QuadFormer: Quadruple Transformer for Unsupervised Domain Adaptation in Power Line Segmentation of Aerial Images Pratyaksh Prabhav Rao*, Feng Qiao*, Weide Zhang, Yiliang Xu, Yong Deng, Guangbin Wu, Qiang Zhang UR, 2024 IEEE #Segmentation#DomainAdapt#PowerLine |
 | STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes Peishan Cong, Xinge Zhu, Feng Qiao, Yiming Ren, Xidong Peng, Yuenan Hou, Lan Xu, Ruigang Yang, Dinesh Manocha, Yuexin Ma CVPR, 2022 arXiv Code #Pedestrian#LiDAR#Dataset |
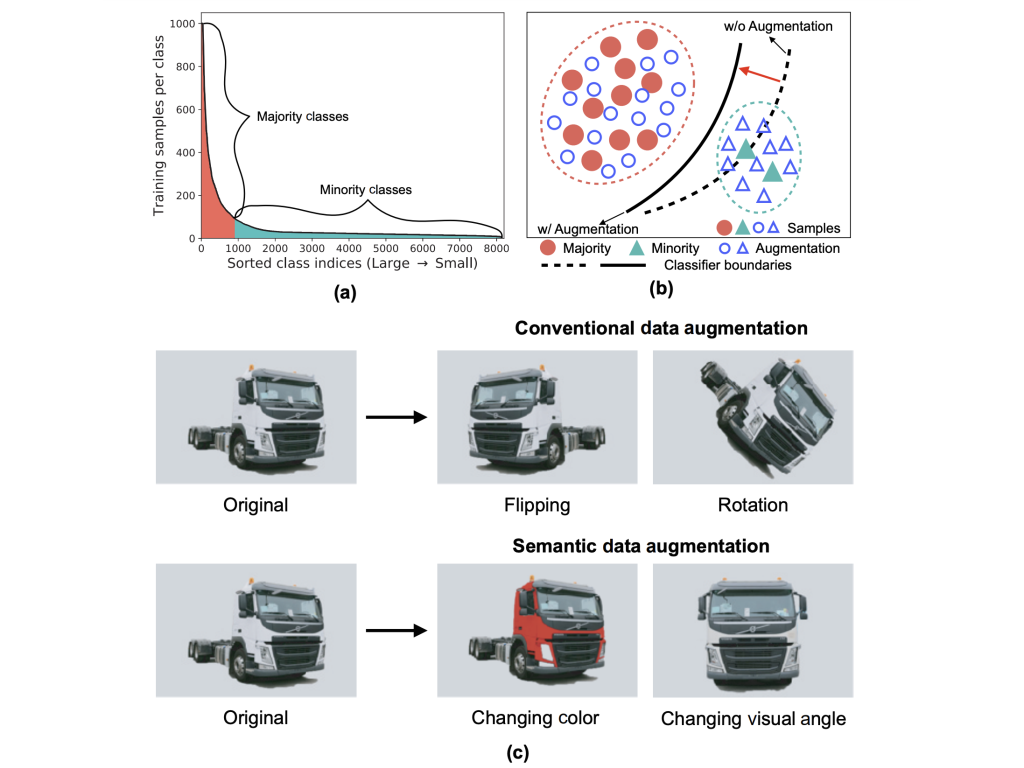 | MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition Shuang Li, Kaixiong Gong, Chi Harold Liu, Yulin Wang, Feng Qiao, Xinjing Cheng CVPR, 2021 arXiv Code #LongTail#MetaLearning |
🌟 Selected work · *Equal contribution
Projects
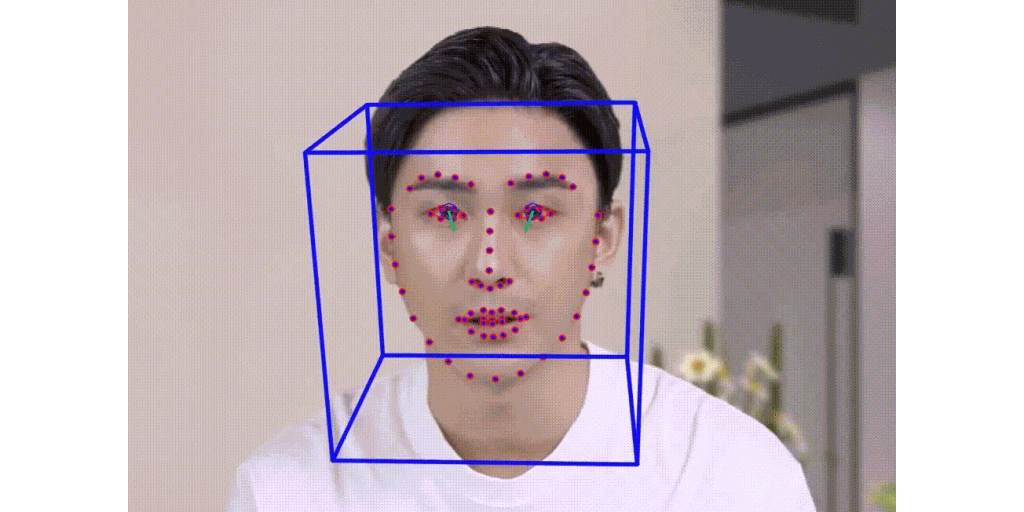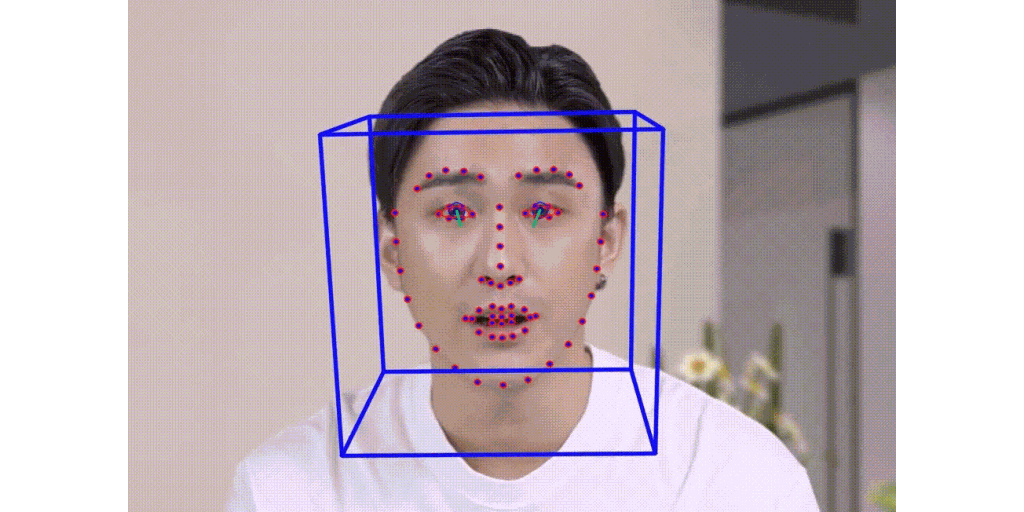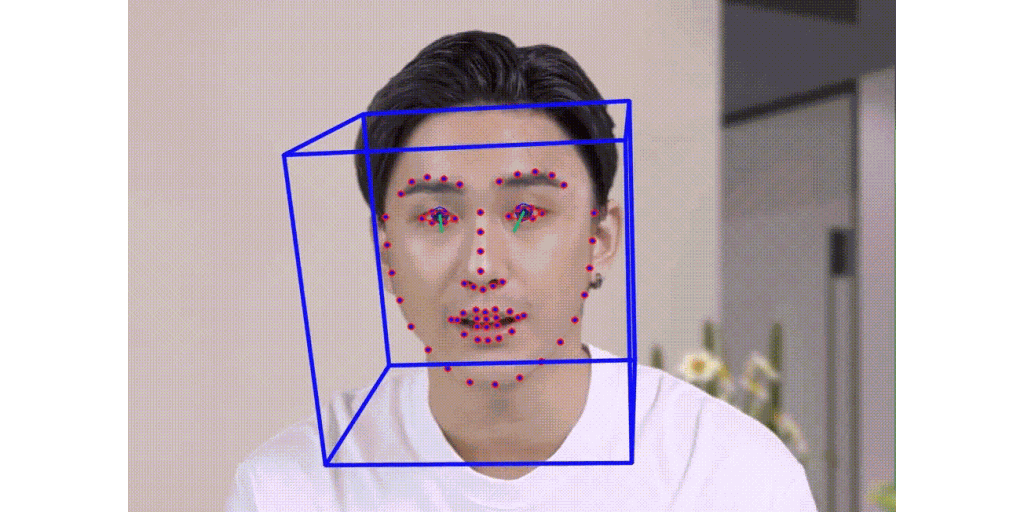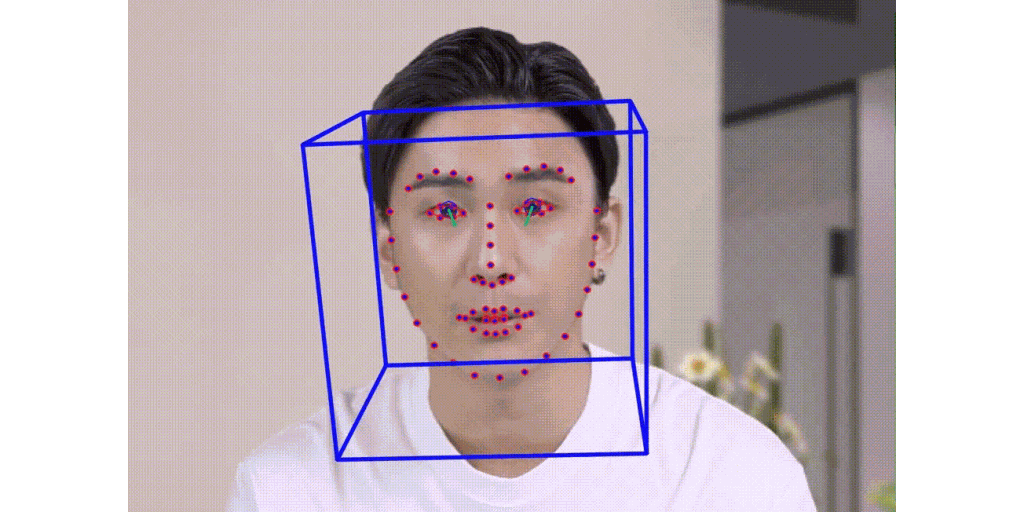
Talking Face Generation
Details
Multi stage talking face generation.

3D Reconstruction of Electric Tower
Details
3D reconstruction of electric tower using aerial images.

3D Reconstruction with Stereo Fisheye Cameras
Details
Unsupervised depth estimation with stereo fisheye cameras.

Self-supervised Depth Estimation using Stereo Cameras
Details
Depth estimation using stereo cameras. Synthetic data is utilized to generate ground truth, and domain adaptation/generalization is employed to ensure excellent performance on real data as well.

3D Object Detection and Tracking using Multi-LiDARs
Details
3D object detection and tracking using multi-lidars. Inputs are sequential point clouds from multi-lidars and the model can get the 3D information of objects including position, size, orientation, class, free space (also as known as drivable area), and lanes. The model is deployed on GPU with TensorRT and SoC chip, which meets the needs of real-time detection.

3D Object Detection and Tracking using Monocular Camera Code
Details
3D object detection and tracking using a monocular camera. The model takes sequential images as inputs and is capable of extracting 3D information about objects, including their position, size, orientation, and class. Deployment on a GPU with TensorRT enables the model to achieve an impressive inference speed of 50 Hz.
Honors and Awards
- ITSC 2024 Best Paper Award
- Outstanding Graduates
- Outstanding scholarship
- Outstanding student leaders
- National Scholarship (top 1%, highest scholarship in China)
Services
Conference Reviewer
CVPR (2023–2026), ICCV (2025), ECCV (2024, 2026), NeurIPS (2026), AAAI (2025, 2026), WACV (2026), BMVC (2026), ITSC (2024, 2025)
Journal Reviewer
TPAMI, T-ITS, T-IV, JAUTO, IJVD